¶ 智能说明书问答解决方案介绍
¶ 大语言模型的局限
ChatGPT作为一个语言模型,实际上没有真正的记忆功能。所谓的对话记忆只是开发者将对话历史向GPT发送消息时将最近的对话历史通过提示工程组发送给ChatGPT。换句话说,如果对话历史超过了大模型的最大上下文,GPT会忘记之前的部分,这是大语言模型共有的局限性。
不同模型目前对于token的限制也不同。例如,gpt-4的限制是32K tokens,而Claude模型则达到了100K tokens,这意味着可以输入约75000字的上下文给GPT,甚至可以直接让GPT理解整部《哈利波特》并回答相关问题。然而这并不能解决所有问题。以Claude模型为例,处理72K tokens上下文的响应速度为22秒。如果我们拥有 GB 级别或更大的文档需要进行 GPT 理解和问答,目前的算力很难带来良好体验,更关键的是目前大语言模型API 的价格是按照 tokens 来收费的,所以输入的上下文越多,其价格越昂贵。
在大模型面对token限制的挑战之外,它对专业领域知识的训练缺乏也是非常明显的短板。尽管这些模型在理解和生成自然语言方面有极高的性能,但它们在处理专业领域的问答时,却往往不能给出明确或者准确的回答。在医学、法律、工程等领域,人工智能可能被要求要理解和运用相当复杂和专业化的知识,然而这在目前的模型中仍是一个巨大的挑战。
¶ 引入向量数据库
在大模型的限制下,开发者们不得不寻找其他的解决方案,而向量数据库就是其中之一。向量数据库的核心思想是将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。这就像我们去参加一场考试一样,如果依赖以往学过的知识去解题,就像我们使用大模型的通用能力去做回答一样。如果我们为大模型搭载了向量数据库,就像我们带着课本去考试一样,遇到用户的问题,就先翻书查找参考资料,找到相关资料再结合问题进行回答。
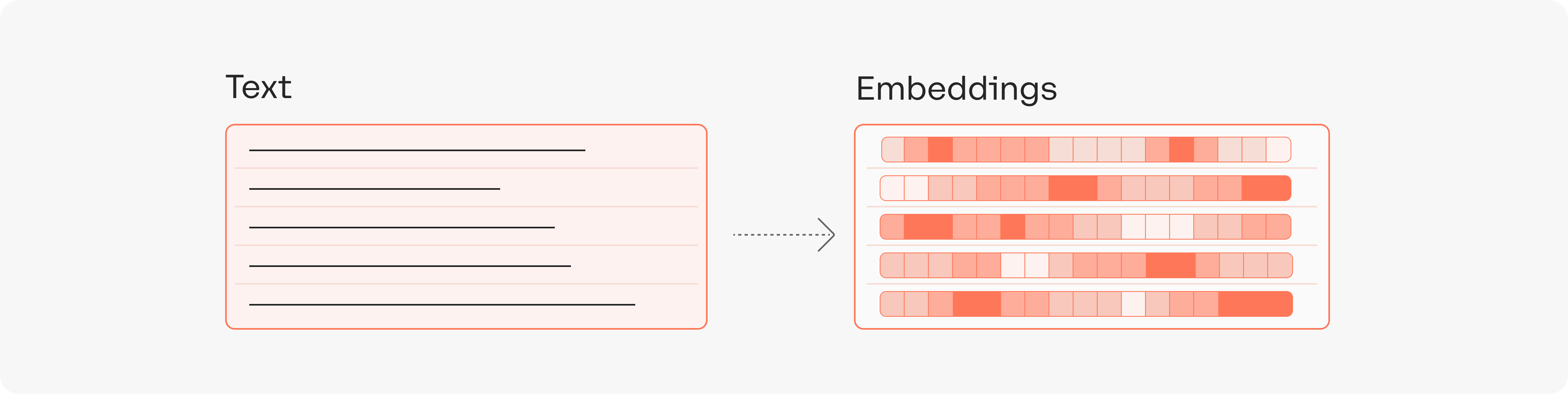
所以,当我们很多文档(例如这份文档是客服培训资料或者操作手册)需要大模型根据它们的内容进行回答时,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给大模型。这样不仅可以大大减少模型的计算量,从而提高响应速度,更重要的是降低成本,并巧妙的减少 tokens 限制所带来的问题。
¶ 智能说明书问答解决方案
以零代码、易用API和一站式服务提供高效的文档索引搜索和应用构建体验。

¶ 快速落地你的应用
加速你的应用落地,几乎零代码即可实现文档索引开始搜索。
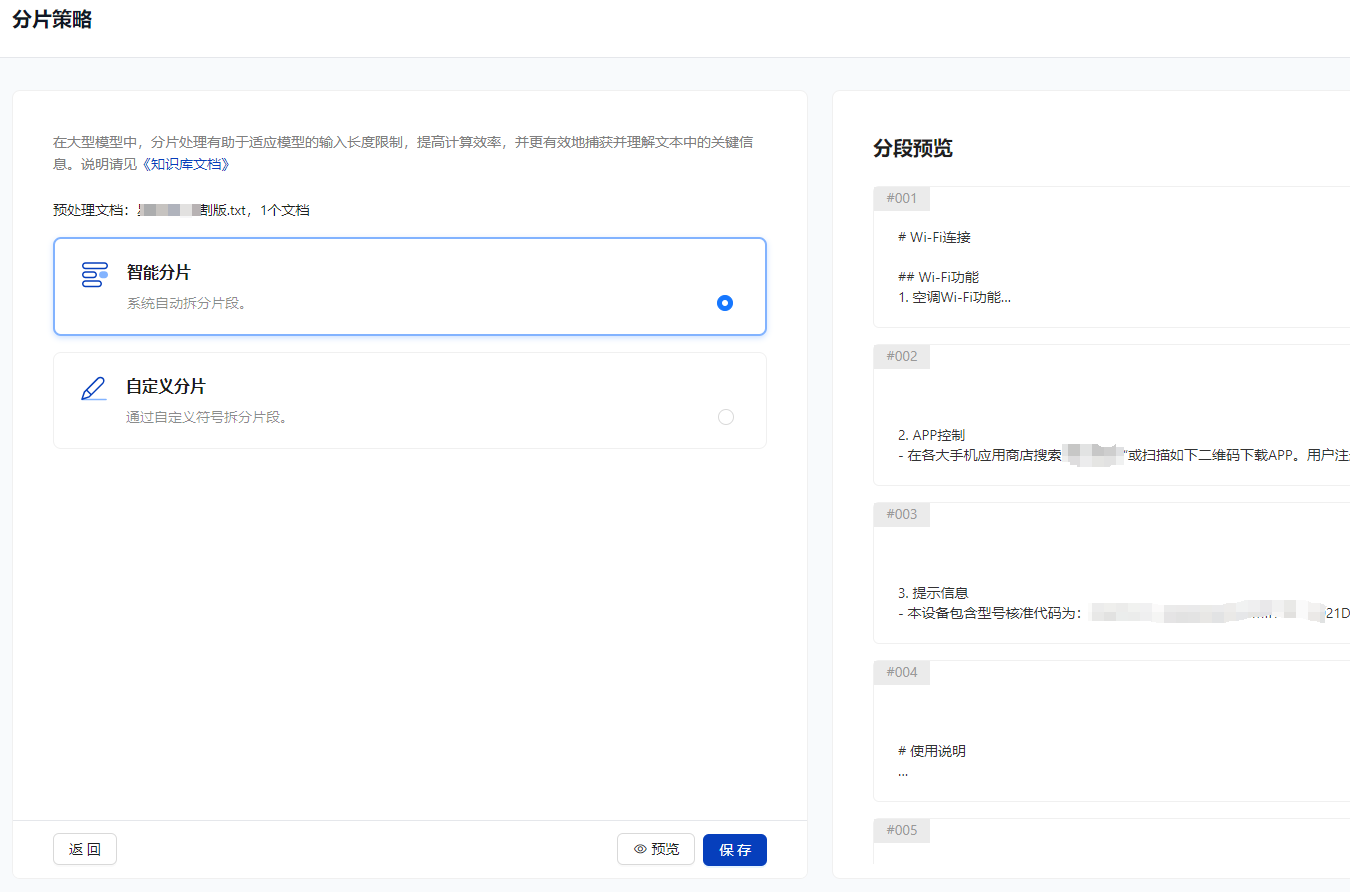
¶ 简单易用的API设计
使用我们的API,你无需关注底层的技术细节,例如输入预处理、向量计算和存储都已经包含在内,只需将文档传入API即可。
curl --location '{{host}}/docs/create' \
--header 'Authorization: <YOUR_PLATFORM_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"index_name": "<YOUR_DATABASE_NAME>",
"documents": [
{
"doc_url": "<YOUR_DOCUMENT_URL>",
"doc_id": "<YOUR_DOCUMENT_ID>",
"chunk_params": {
"chunk_method": "separator",
"separator":"/n"
}
}
]
}'
¶ 强大的向量模型
模型通过千万级的中文句数据集进行训练,包含中文百科,金融,医疗,法律,新闻,学术等多个领域共计 2200W 句对样本。英文训练集使用145W 英文三元组数据集进行训练。支持中英双语的同质文本相似度计算,异质文本检索等功能
¶ 全链路一站式解决方案
从文档转换、分片策略、建立索引、效果测试、提示工程、应用构建等,我们平台提供了一站式的解决方案和最佳实践指导手册。
智能说明书问答方案使用地址:https://platform.listenai.com/